Smithsonian Institution builds AI trial to capture biodiversity data from historic research
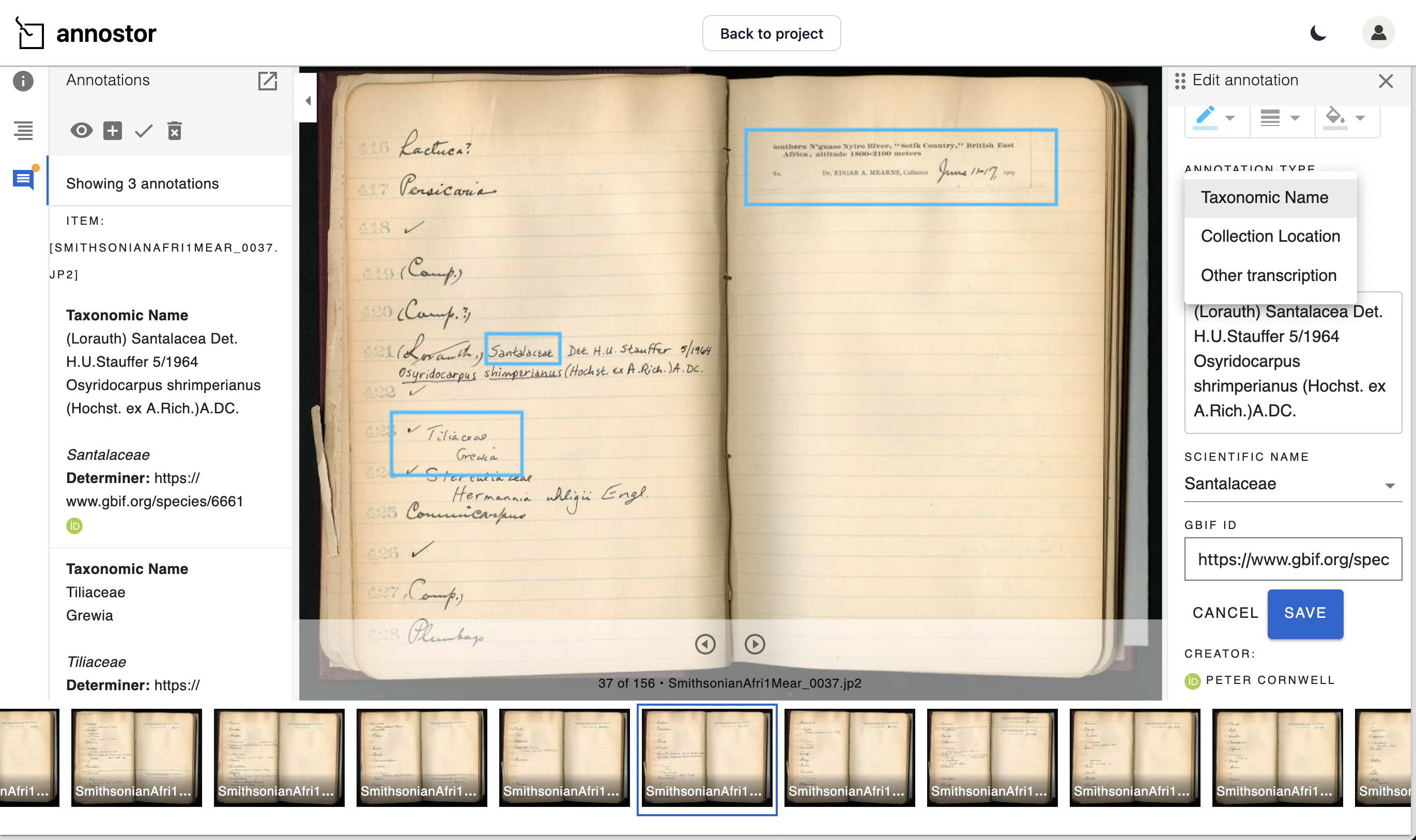
During 2024 Smithsonian Institution researchers working with the Biodiversity Heritage Library (BHL) extracted structured taxonomic data from large numbers of historic field notebooks.
This material is a crucial resource for understanding historical populations and habitats, which have now been degraded by polution and climate change.
Creating a digital corpus from the primarily hand-written material and pasted-in photographs, the project used AI to extract texts and provided workflows for human correction of text recognition errors and for experts to confirm specimen identifications.




Extraction of biodiversity data using a pipeline of AI products
rapidly-advancing AI workflows extract structured data from handwritten field notebooks, creating access for researchers to historic species populations and habitat conditions
annostor provides human–in-the-loop validation workflows
annostor's hybrid workflows combine AI speed at scale with expert review, to establish scientific facts
Integrating Al data derivatives with long-term biodiversity infrastructure
integrating![]() and
and![]() annotation
the InvenioRDM repository enables
seamless connection with GBIF and
GNA, and guarantees long-term access
and protection of investment
annotation
the InvenioRDM repository enables
seamless connection with GBIF and
GNA, and guarantees long-term access
and protection of investment
Creating new FAIR biodiversity data resources
unlocking critical historic records using AI analysis validated via annostor workflows, creates freely-accessible FAIR resources for researchers worldwide, and for education
Integrating AI outputs with source materials for long-term preservation
Working with annostor the Smithsonian team developed a repository providing IIIF image services for the field notebook page imagery and supporting Web Annotation Data Model (WADM) annotation. They imported the corrected AI-generated texts of the handwritten notes to create annotations anchored to the digitised pages, and then created links to the Global Biodiversity Information Framework (GBIF) using the Global Names Architecture (GNA).
They imported the corrected AI-generated texts of the handwritten notes to create annotations anchored to the digitised pages, and then created links to the Global Biodiversity Information Framework (GBIF) using the Global Names Architecture (GNA).

Connecting historic field observations with global data resources using Persistent IDentifiers
Extending this investigation during 2025, the Smithsonian analysed tens of thousands of heritage biodiversity images—originally deposited in BHL from the Flickr Foundation—and created AI profiles of the organisms and plants discovered. These profiles, together with the high-resolution digital imagery were added to the new repository to automatically create new collections of standards-based annotation records.
Hybrid workflows were then developed to support human-in-the-loop identification of the specimens via GBIF and GNA—producing a new corpus of historic field observation records having free access to the global scientific community.